Core Development Concepts > CI/CD
Testing
Learn what are cloud infrastructure state files and how to properly store them.
- how to organize and run tests for your applications
Get your CI/CD set up in no time with the built-in CI/CD scaffold.
Application Testing - a Brief Overview
One of the fundamental parts of every CI/CD workflow are tests, which essentially, help us ensure that our application is working the way it’s supposed to.
“Does the login system work?”, “Is the price calculated correctly?”, or “Is a particular page rendered correctly?”, are just some of the examples of parts of our application that we can inspect every time our tests are run, both in manual and automated fashion.
Different Types of Tests
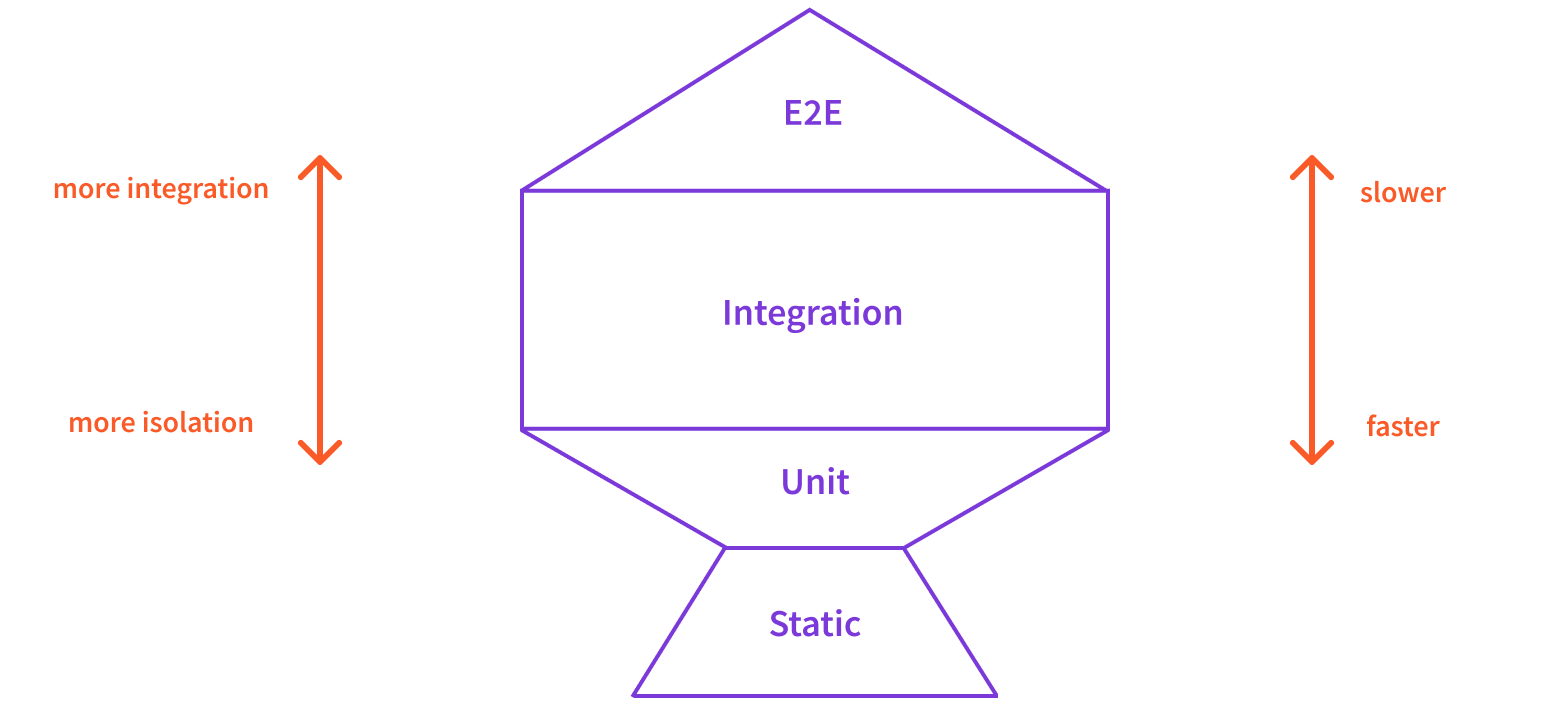
There are three fundamental types of tests we usually write while developing our application: unit, integration, and end-to-end (E2E). With the three, these days more and more, developers are also incorporating something called static tests.
Let’s briefly cover each type.
Unit Tests
Unit tests are the smallest when it comes to scope, and, as the name itself suggests, are created to ensure a small unit of our application is working as expected. For example, we might test whether a particular function, given a specific set of arguments, returns the correct result.
The code we’re testing here does not interact with other moving parts in your application or external services, like for example a database.
Typically, unit tests are the fastest to run.
Integration Tests
As soon as the code we’re testing interacts with other moving parts or external services, like for example a database, we’re talking about integration tests.
Typically, because external services need to be deployed, running these is slower than running unit tests. But, they can provide more confidence that our application is working, simply because of a much greater coverage than what unit tests provide.
End-to-End (E2E) Tests
Finally, the end-to-end (E2E) tests the whole application, using it as an actual user would do it. Some examples are testing a GraphQL API or when talking about frontend development, simulating a user completing a signup form.
Running these tests is slower than both integration and unit tests, but they can provide the best result when it comes to ensuring that our application is working as expected. Simulating a user completing a user signup flow not only ensures our user interface is working as it should be, but also the backend HTTP API, with which the form is interacting.
Static Tests
Static tests are used to check issues in our code, without actually executing it. For example:
- are there any issues on the types-level (TypeScript
 )
) - is there code that is redundant or code that cannot be reached (ESLint)
- is our code following the defined formatting rules (Prettier)
All of the mentioned tools (and some others) are already included and configured for you in every Webiny project. Check out the Tools and Libraries key topic to learn more.
Usually, these tests are reasonably fast to run, and sometimes, even the fastest.
An Overview of Different Types of Tests
The following diagram, sometimes called the Testing Trophy, shows all four types of tests we’ve just explained.
 Environments.
Environments.Running Tests in a CI/CD Workflow
Now that we’ve briefly covered different the fundamental types of tests, let’s see how we can run them in a CI/CD workflow.
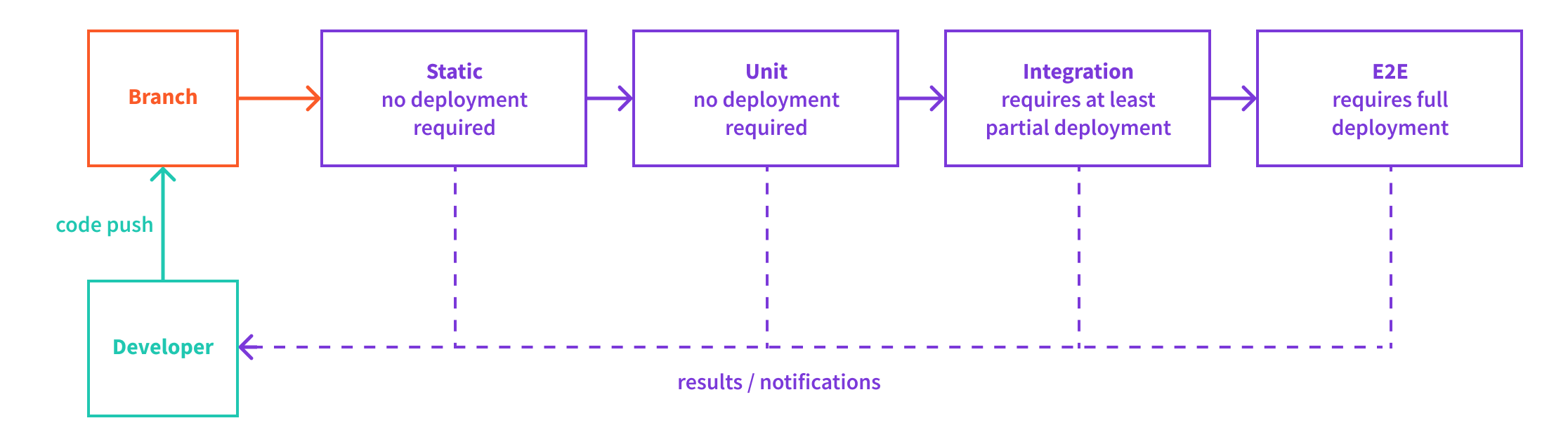
The Order of Execution and Optimizing for Fast Feedback Loop
While designing our CI/CD workflow, one of the elements we need to pay attention to is how fast it is being executed or in other words, how fast it can provide valuable feedback to our organization.
Because of this, it is recommended that we first run tests that take the least amount of time to finish. This is because if one of those fail, in most cases, there is no reason to continue with the rest of the tests, which take more time to finish.
So, with that in mind, usually we want to start with running our static and unit tests. As these don’t rely on any external services, these will always require the least amount of time to finish.
Once static and unit tests are passing, we want to continue with integration tests. Note that, in order to perform these, we’ll most probably need to deploy external services or supporting cloud infrastructure resources. With serverless technologies this will definitely be the case, as testing against real services (and not emulations) will provide the highest level of accuracy and confidence.
The requirement of having to deploy external services or supporting cloud infrastructure resources in order to run integration tests makes them slower to finish. But do note that sometimes it’s acceptable to only deploy the needed subset of external resource, which can make this step a bit faster. We’ll cover this in the following sections.
Finally, end-to-end (E2E) tests should be run last, as they almost always require the most amount of time to finish. Here we don’t have the option to partially deploy external service or supporting cloud infrastructure resources. In order to get the full picture, we need to deploy everything.
The following diagram shows the recommended order in which different types of tests can be run in a CI/CD workflow:
 Environments.
Environments.Points of Execution
When designing a CI/CD workflow, there are a couple of key points in which the tests are usually run.
Pull Requests (PRs)
As we’ve learned in the Version Control section, in GitHub flow, developers integrate new application changes via pull requests (PRs). So, this will be the first line of defense where we’ll want to ensure the proposed code changes don’t introduce unwanted results or any types of regressions. Only once all of the tests have passed and the code was reviewed by one or more members of the team, it should be allowed for a PR to be merged into one of the long-lived branches.
Note that, since integration and end-to-end (E2E) tests almost always require an external service or cloud infrastructure resources to be deployed, in order to run tests on PRs, we usually deploy temporary or sometimes called, ephemeral, environments. More on this can be found in the following section.
Pushes to Long-Lived Branches
Once a PR has been merged into one of the long-lived branches (dev, staging, prod), it’s recommend that all of the tests are run once again, but this time, against the already deployed long-lived environment, if possible. In other words, we don’t want to provision a temporary environment in order to run these (like we did with PRs). We want to ensure that the system that’s already live and serving users, is working as it’s supposed to.
Although there might be no differences between the code in the merged PR and the long-lived branch, it’s still possible that an environment-specific configuration is incorrectly specified or simply missing, in the branch (and deployed environment) into which the PR was merged. These may include values like API keys to 3rd party services, different configuration values for the services we developed on our own, and more.
In some organizations, the point in which a PR has been merged and deployed, could also be the point in which QA teams start their manual testing, especially if we’re talking about merges happening against staging or production branches.
Merging strategies are covered in the upcoming Workflows guide.
Local Development
It’s useful to mention that developers should also be able to run tests without the need of an external CI/CD workflow. This is important when making code changes locally, where we want to have a fast feedback loop and quickly ensure we aren’t breaking any existing functionality. We certainly don’t want to end up waiting for the CI/CD workflow to tell us that.
Deploying Short-Lived (Ephemeral) Environments for Testing Purposes
As mentioned in the previous Points of Execution section, tests can be run upon submitting PRs. And since integration and end-to-end (E2E) tests require cloud infrastructure resources to be deployed, we end up with a need to deploy our project into a short-lived, or sometimes also called an ephemeral, environment.
In other words, once a PR has been opened, we do the following:
- deploy the project into an ephemeral environment
- run all tests upon opening the PR and submitting and additional changes
- once the PR has been closed, destroy the deployed ephemeral environment
Apart from enabling us to run tests against real cloud infrastructure resources, this approach also provides a “live preview” of the changes we’re about to merge. This can be very handy, for example, when the change that’s about to get merged is more of a cosmetic nature, which might require several iterations and manual checks before it’s approved.
Note that, in order to deploy these ephemeral environments, we suggest a separate cloud (AWS) account is created. It should not be linked in any way with the accounts used for deploying into dev, staging, and prod environment.
Also, since we’re using a single cloud (AWS) account, in which we might have multiple ephemeral environments deployed at the same time (because of multiple active PRs), upon deploying the project, we suggest that the name of the environment is dynamically generated. Even better, the name of the environment can be inherited from the PR number, which should we should be able to retrieve while our CI/CD workflow is running.
When we talk about multiple environment deployments, it’s important to note that we’re talking about deploying multiple copies of our project, both in terms of the application code and, more importantly, needed cloud infrastructure resources.
In some cases, doing this can incur additional cost.
Testing Cloud Infrastructure Changes
With serverless technologies and cloud development in general, one thing that has significantly changed for developers is the fact that they now get to have more freedom and impact when it comes to deploying necessary cloud infrastructure resources. It’s not unusual for a particular fix or feature to introduce a change or two in the existing deployed cloud infrastructure.
For that reason, we need to take necessary precaution measures that ensure our cloud infrastructure is not negatively affected in any way. A couple of examples of this might be:
- deletions of mission critical cloud infrastructure resources like databases, identity pools, file storage, and similar
- over-provisioning (using more of something than you actually need)
- not respecting the required general and potentially internal security policies
- not following some of the established internal conventions
- and more…
That’s why we recommend that you perform various cloud-infrastructure related inspections before merging any code changes into long-lived branches. The following are some of the approaches you can utilize.
Preview Deployments
Once a PR has been submitted, it’s useful to preview the deployment that’s about to happen after the PR is merged.
The first point where we’re able to do that is when a PR has been submitted against the dev long-lived branch.
By simply running the following command …
yarn webiny deploy --env {env} --preview…we can get a list of all cloud resources that will change, once the code has been merged and deployment has finished.
Do note that, when setting up this step, proper cloud account credentials will need to be passed. If we are previewing deployment for the dev environment, then we need to use the credentials used for deploying into that environment. The same goes for staging and prod branches / environments.
Read more about the preview command in the Preview Deployments guide.
Mark Mission Critical Cloud Infrastructure Resources as Protected
By default, Webiny uses Pulumi as the default infrastructure as code (IaC) framework, which allows us to mark one or more cloud infrastructure resources as protected:
The
protectoption marks a resource as protected. A protected resource cannot be deleted directly. Instead, you must first setprotect: falseand runpulumi up. Then you can delete the resource by removing the line of code or by runningpulumi destroy. The default is to inherit this value from the parent resource, andfalsefor resources without a parent.
Within a Webiny project, note that the pulumi up and pulumi destroy commands are run via the webiny deploy and webiny destroy commands, respectively.
Note that some of the cloud infrastructure resources that Webiny deploys for you, such as the Amazon DynamoDB table or the Amazon Cognito User Pool are already marked as protected.
To learn more about the necessary cloud infrastructure resources Webiny is relying on, check out the Cloud Infrastructure section.
Write Cloud Infrastructure Code Tests
Since the Pulumi framework enables us to declare our cloud infrastructure via code, we can write tests for it.
For more instructions on how to write these, we suggest you visit the official Pulumi documentation. For any potential integration-related questions, feel free to contact us.
Use Pulumi's Policy as Code (CrossGuard)
Another feature that the Pulumi framework offers is Policy As Code (CrossGuard):
CrossGuard empowers you to set guardrails to enforce compliance for resources so developers within an organization can provision their own infrastructure while sticking to best practices and security compliance. Using Policy as Code, you can write flexible business or security policies.
Using CrossGuard, organization administrators can apply these rules to particular stacks within their organization. When policies are executed as part of your Pulumi deployments, any violation will gate or block that update from proceeding.
In order to get started, we recommend you visit the official Pulumi documentation. For any potential integration-related questions, feel free to contact us.
FAQ
Deploying Ephemeral Environments Takes a Long Time Finish, What Can I Do About It?
It’s true that certain cloud infrastructure resources take more time to be fully deployed, for example Amazon CloudFront distributions or Amazon Elasticsearch clusters. Naturally, because of this, the execution speed of our CI/CD workflows also gets a negative impact as well.
Hopefully, this is something that will get improved over time by your cloud provider. But still, in order to tackle this problem now, one approach we recommend is to deploy some of the cloud infrastructure resources separately. You could even do this manually and not within the existing Pulumi code you have in your project.
Once you have that, the projects that you deploy into ephemeral environments could be configured and instructed to rely on these already deployed cloud infrastructure resources, instead of deploying them on their own.
So, in case of the Amazon Elasticsearch, we’d deploy a single cluster, after which all projects that are deployed into an ephemeral environment would use that, instead of deploying the cluster on their own.
For some cloud infrastructure resources this approach makes more sense, for some less or no sense. It’s up to you to figure out if this approach can work for your particular project.
Can't I Use Cloud Emulations Instead of Deploying Cloud Infrastructure Resources?
Sure, there are different tools that try to emulate the cloud and, sort of, enable local development. But the main problem with these solutions is that they can’t really keep pace with the developments happening in different clouds, and most importantly, will never be able to 100% emulate the actual service. This poses a problem because, while developing your application, it might seem everything works. But, when you deploy your application into the cloud, different issues may start to occur.
Because of this, we’d always recommend testing against real services.
My Project Uses Webiny Applications, and Every Time I Deploy It Into an Ephemeral Environment, When I Open the Admin Area for the First Time, I Have to Go Through the Installation Wizard.
Deploying your Webiny project into an ephemeral environments means we end up with a brand new system, with no data, nor configurations for different Webiny applications that you might have enabled, like Security, Page Builder, File Manager, and so on. So unfortunately, having to go through installation wizard in our browser cannot be avoided.
But, note that while we’re completing the wizard, a series of GraphQL API mutations are issued in the background. So, in order to automate the installation phase, we can create a script that’s executed as soon as the API project application is deployed, which will just execute all of the GraphQL API mutations for us. Meaning, once we open the Admin Area for the first time.
Learn more about the API project application in the Cloud Infrastructure key topics section.
How Can I Insert Production Data Into a Project Deployed Into thestagingEnvironment (Data Dumps)?
Writing custom scripts is probably the best answer we can give you here, as every system is specific.
Essentially, you’d be copying all of the data, from different services, from one environment into another. And although at first this may not sound too complicated, you may encounter different problems because of the following:
- if you’ve followed the general recommendation, different cloud (AWS) accounts are used for different long-lived environments
- copying data, in some cases, also includes copying of files, Cognito users, and more
- we need to decide which data should be copied and whether it should be identical or modified in the process
As you can see, a simple “copy all of the data” script can very quickly become a complex script that requires a lot of knowledge about the project itself and the specific requirements that are in front of you.